6 Advancing Statistics in R
install.packages("ggplot2", repos = "https://cran.us.r-project.org")
install.packages("dplyr", repos = "https://cran.us.r-project.org")
install.packages("ggfortify", repos = "https://cran.us.r-project.org")6.1 The two-way ANOVA
- the two-way ANOVA differs from the one-way version in that it involves two categorical/explanatory variables
- the response variable in the two-way ANOVA may vary with both explanatory variables
- if the way it varies depends on the other explanatory variable, then this phenomenon is known as a statistical interaction
Read in data:
urlfile06a="https://raw.githubusercontent.com/apicellap/data/main/growth.csv"
growth.moo<-read.csv(url(urlfile06a))
glimpse(growth.moo)## Rows: 48
## Columns: 3
## $ supplement <chr> "supergain", "supergain", "supergain", "supergain", "contro…
## $ diet <chr> "wheat", "wheat", "wheat", "wheat", "wheat", "wheat", "whea…
## $ gain <dbl> 17.37125, 16.81489, 18.08184, 15.78175, 17.70656, 18.22717,…6.1.1 Cow Growth data
- this dataset deals with cows on different diets
- cows were fed one of three diets:
- wheat, oats, or barley
- each diet was then enhanced with one of four supplements:
- supergrain, control, supersupp, agrimore
- each diet combination had 3 biological replicates (cows)
- cows were fed one of three diets:
Coerce two of the variables into factors:
growth.moo$supplement <-as.factor(growth.moo$supplement)
growth.moo$diet <-as.factor(growth.moo$diet)
levels(growth.moo$diet)## [1] "barley" "oats" "wheat"
levels(growth.moo$supplement)## [1] "agrimore" "control" "supergain" "supersupp"- in both of the previous code chunks the output is in alphabetical order
- R always declares the first level alphabetically the reference level
- in the case of the supplement variable, control must be made the reference level
- this can be accomplished using the
relevel()function:
- this can be accomplished using the
growth.moo <- mutate(growth.moo,
supplement = relevel(supplement, ref = "control"))
levels(growth.moo$supplement)## [1] "control" "agrimore" "supergain" "supersupp"Create summary dataframe:
## `summarise()` has grouped output by 'diet'. You can override using the
## `.groups` argument.
sumMoo## # A tibble: 12 × 3
## # Groups: diet [3]
## diet supplement meanGrow
## <fct> <fct> <dbl>
## 1 barley control 23.3
## 2 barley agrimore 26.3
## 3 barley supergain 22.5
## 4 barley supersupp 25.6
## 5 oats control 20.5
## 6 oats agrimore 23.3
## 7 oats supergain 19.7
## 8 oats supersupp 21.9
## 9 wheat control 17.4
## 10 wheat agrimore 19.6
## 11 wheat supergain 17.0
## 12 wheat supersupp 19.7
ggplot(sumMoo, aes(x=supplement, y=meanGrow,
colour = diet, #adds color by group
group = diet)) + #
geom_point() +
geom_line() + #connects the dots in each dataset
theme_bw()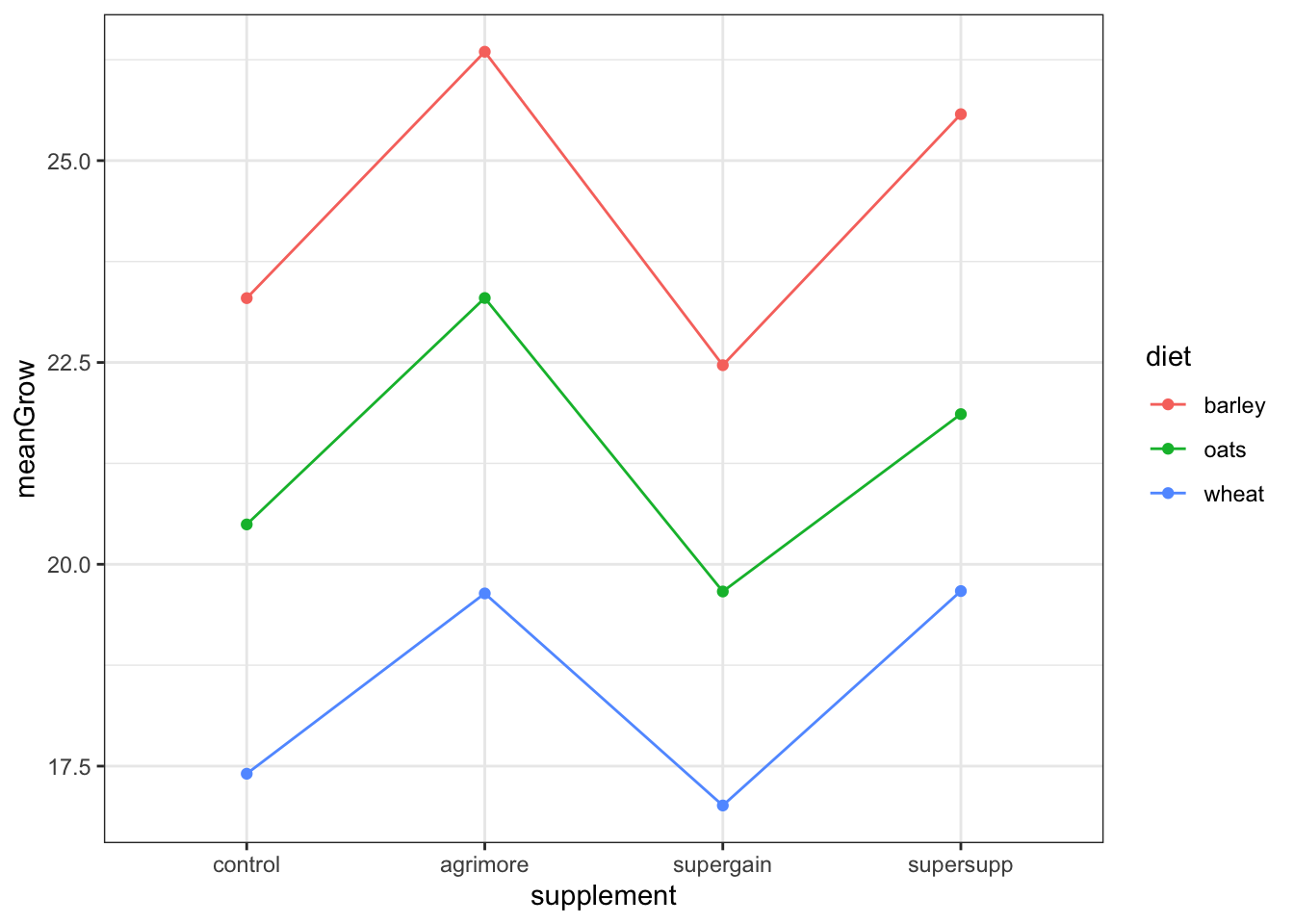
the different supplements might have growth stimulating effects
the barley and/or oats diets might be better in stimulating growth relative to the wheat diet
since the lines are about parallel with each other, then we can probably rule out interaction effects. This means the effect of supplement probably does not depend on the effect of diet
but there might be an additive effect
null hypothesis: the effect of supplement type does not depend on diet
Create a model to evaluate the null hypothesis:
model_cow <- lm(gain ~ diet * supplement,
data=growth.moo)
model_cow##
## Call:
## lm(formula = gain ~ diet * supplement, data = growth.moo)
##
## Coefficients:
## (Intercept) dietoats
## 23.2966499 -2.8029851
## dietwheat supplementagrimore
## -5.8911317 3.0518277
## supplementsupergain supplementsupersupp
## -0.8305263 2.2786527
## dietoats:supplementagrimore dietwheat:supplementagrimore
## -0.2471088 -0.8182729
## dietoats:supplementsupergain dietwheat:supplementsupergain
## -0.0001351 0.4374395
## dietoats:supplementsupersupp dietwheat:supplementsupersupp
## -0.9120830 -0.0158299- function asks if the growth depends on diet, supplement, or an interaction between diet:supplement
Check assumptions:
autoplot(model_cow, smooth.colour = NA)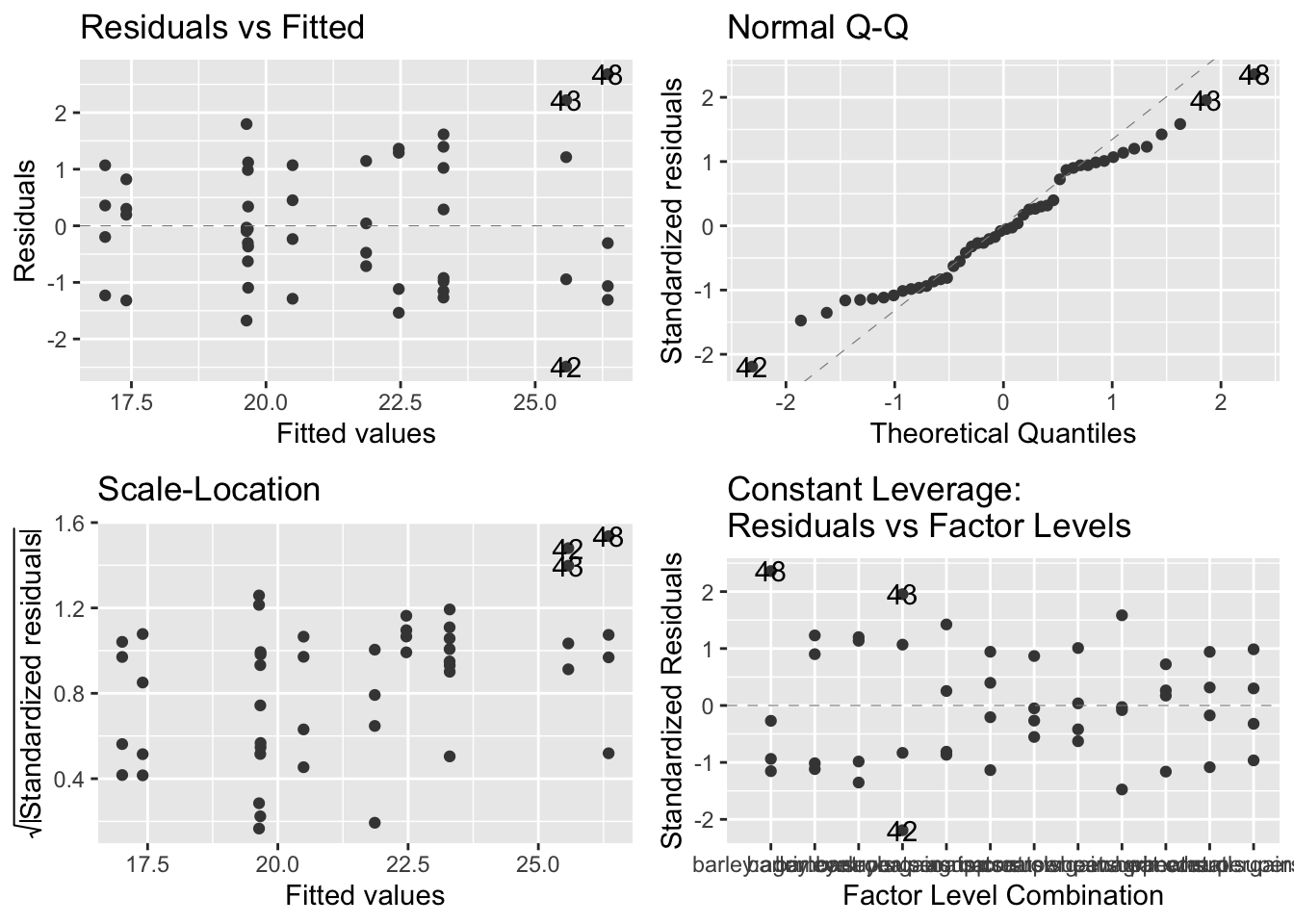
- plot output: they look okay, but not ideal
- top left - no pattern that would suggest model is inappropriate
- top right - less than ideal because the positive and negative residuals are smaller than expected but the general linear model will be able to deal with these deviations from normality
- bottom left - looks fine, virtually no pattern
- bottom right - no serious outliers, looks fine
Create ANOVA table:
anova(model_cow)## Analysis of Variance Table
##
## Response: gain
## Df Sum Sq Mean Sq F value Pr(>F)
## diet 2 287.171 143.586 83.5201 2.999e-14 ***
## supplement 3 91.881 30.627 17.8150 2.952e-07 ***
## diet:supplement 6 3.406 0.568 0.3302 0.9166
## Residuals 36 61.890 1.719
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1- the diet:supplement row shows a small F value and a p value of 0.91 (way bigger than 0.05)
- there is no statistically significant effect contributed by the two variables together
- revisit the importance of a big F value
Create summary table:
summary(model_cow)##
## Call:
## lm(formula = gain ~ diet * supplement, data = growth.moo)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.48756 -1.00368 -0.07452 1.03496 2.68069
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 23.2966499 0.6555863 35.536 < 2e-16 ***
## dietoats -2.8029851 0.9271390 -3.023 0.00459 **
## dietwheat -5.8911317 0.9271390 -6.354 2.34e-07 ***
## supplementagrimore 3.0518277 0.9271390 3.292 0.00224 **
## supplementsupergain -0.8305263 0.9271390 -0.896 0.37631
## supplementsupersupp 2.2786527 0.9271390 2.458 0.01893 *
## dietoats:supplementagrimore -0.2471088 1.3111726 -0.188 0.85157
## dietwheat:supplementagrimore -0.8182729 1.3111726 -0.624 0.53651
## dietoats:supplementsupergain -0.0001351 1.3111726 0.000 0.99992
## dietwheat:supplementsupergain 0.4374395 1.3111726 0.334 0.74060
## dietoats:supplementsupersupp -0.9120830 1.3111726 -0.696 0.49113
## dietwheat:supplementsupersupp -0.0158299 1.3111726 -0.012 0.99043
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.311 on 36 degrees of freedom
## Multiple R-squared: 0.8607, Adjusted R-squared: 0.8182
## F-statistic: 20.22 on 11 and 36 DF, p-value: 3.295e-12- output:
- the intercept is the reference point for the table. it’s the barley-control because barley is alphabetically first
- and we already set the reference to be the control
- the Estimate column is the difference between the reference level and the level in each row
Generate new summary table:
sumMoo <- growth.moo %>%
group_by(diet,supplement) %>%
summarise(meanGrow = mean(gain),
seGrow =
sd(gain)/
sqrt(
n())) #n() counts the number of observations in each group ## `summarise()` has grouped output by 'diet'. You can override using the
## `.groups` argument.
#side note: n() will count observations even if they have missing values
sumMoo ## # A tibble: 12 × 4
## # Groups: diet [3]
## diet supplement meanGrow seGrow
## <fct> <fct> <dbl> <dbl>
## 1 barley control 23.3 0.703
## 2 barley agrimore 26.3 0.919
## 3 barley supergain 22.5 0.771
## 4 barley supersupp 25.6 1.06
## 5 oats control 20.5 0.506
## 6 oats agrimore 23.3 0.613
## 7 oats supergain 19.7 0.349
## 8 oats supersupp 21.9 0.413
## 9 wheat control 17.4 0.460
## 10 wheat agrimore 19.6 0.710
## 11 wheat supergain 17.0 0.485
## 12 wheat supersupp 19.7 0.475Replot the data with standard error bars:
ggplot(sumMoo, aes(x=supplement, y=meanGrow,
colour = diet, #adds color by group
group = diet)) + #
geom_point() +
geom_line() + #connects the dots in each dataset
geom_errorbar(aes(ymin = meanGrow - seGrow,
ymax = meanGrow + seGrow), width = 0.1) +
theme_bw()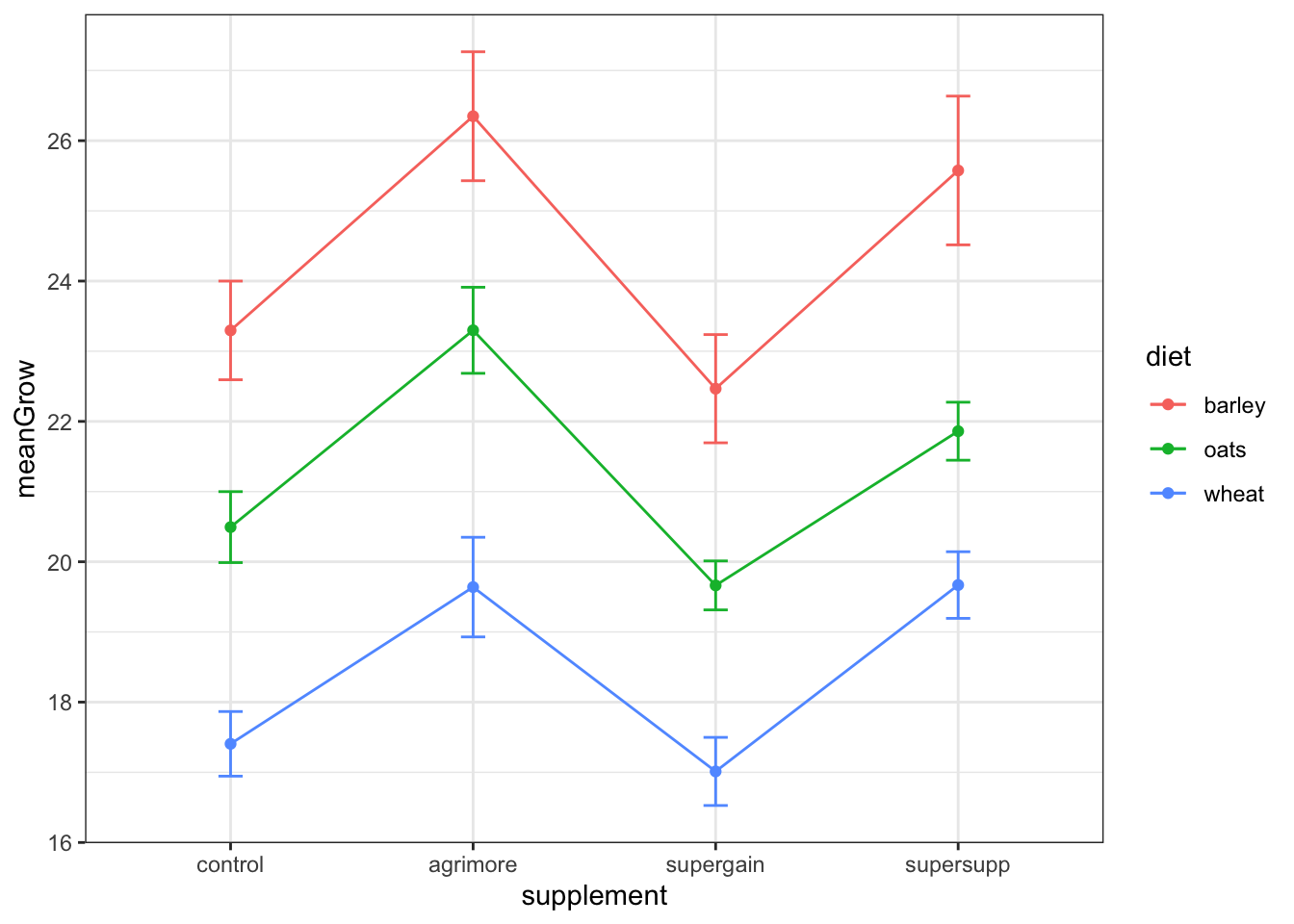
6.2 Analysis of Covariance (ANCOVA)
- this linear model is unique in that it combines a categorical explanatory variable with a continuous explanatory variable
Read in data:
urlfile06b="https://raw.githubusercontent.com/apicellap/data/main/limpet.csv"
limp<-read.csv(url(urlfile06b))
glimpse(limp)## Rows: 24
## Columns: 3
## $ DENSITY <int> 8, 8, 8, 8, 8, 8, 15, 15, 15, 15, 15, 15, 30, 30, 30, 30, 30, …
## $ SEASON <chr> "spring", "spring", "spring", "summer", "summer", "summer", "s…
## $ EGGS <dbl> 2.875, 2.625, 1.750, 2.125, 1.500, 1.875, 2.600, 1.866, 2.066,…- this dataset involves egg production by limpets
- there are 4 density conditions in two production seasons
- the response (y) variable is egg production
- the independent (x) variables include:
- density (continuous)
- season (categorical)
- this is a study of density dependent reproduction
- Does density dependence of egg production differ between the spring and summer seasons?
Coerce variable into a factor:
limp$SEASON <-as.factor(limp$SEASON)
is.factor(limp$SEASON) #allows you to check that the coercion worked ## [1] TRUEStart by plotting the data:
ggplot(limp, aes(x = DENSITY, y = EGGS, colour=SEASON)) + #colour - gives color to the two levels of the categorical variable, Grazing
geom_point() +
scale_color_manual(values = c(spring = "green", summer = "red")) +
xlab("Limpet Density") +
ylab("Eggs produced") +
theme_bw() 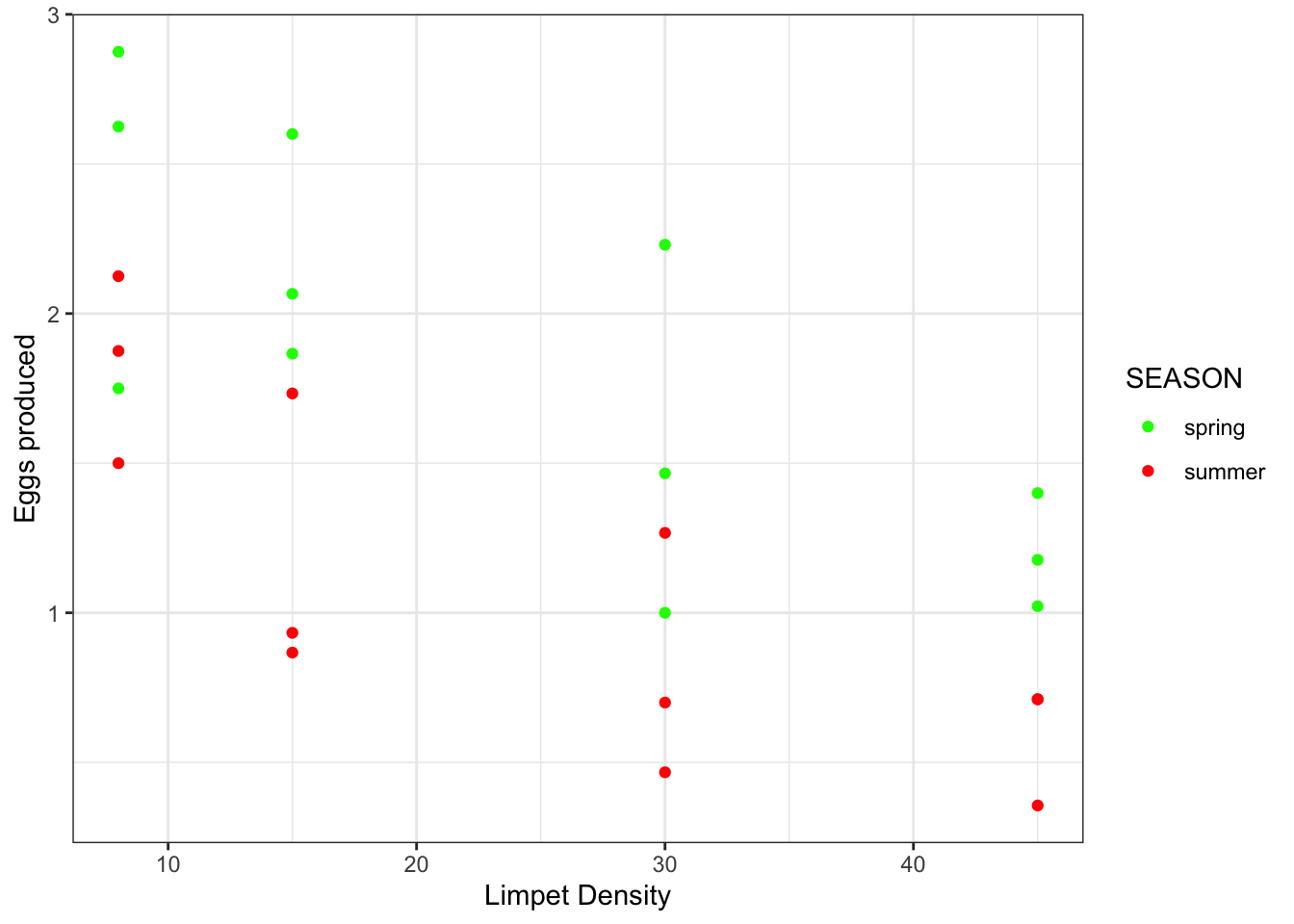
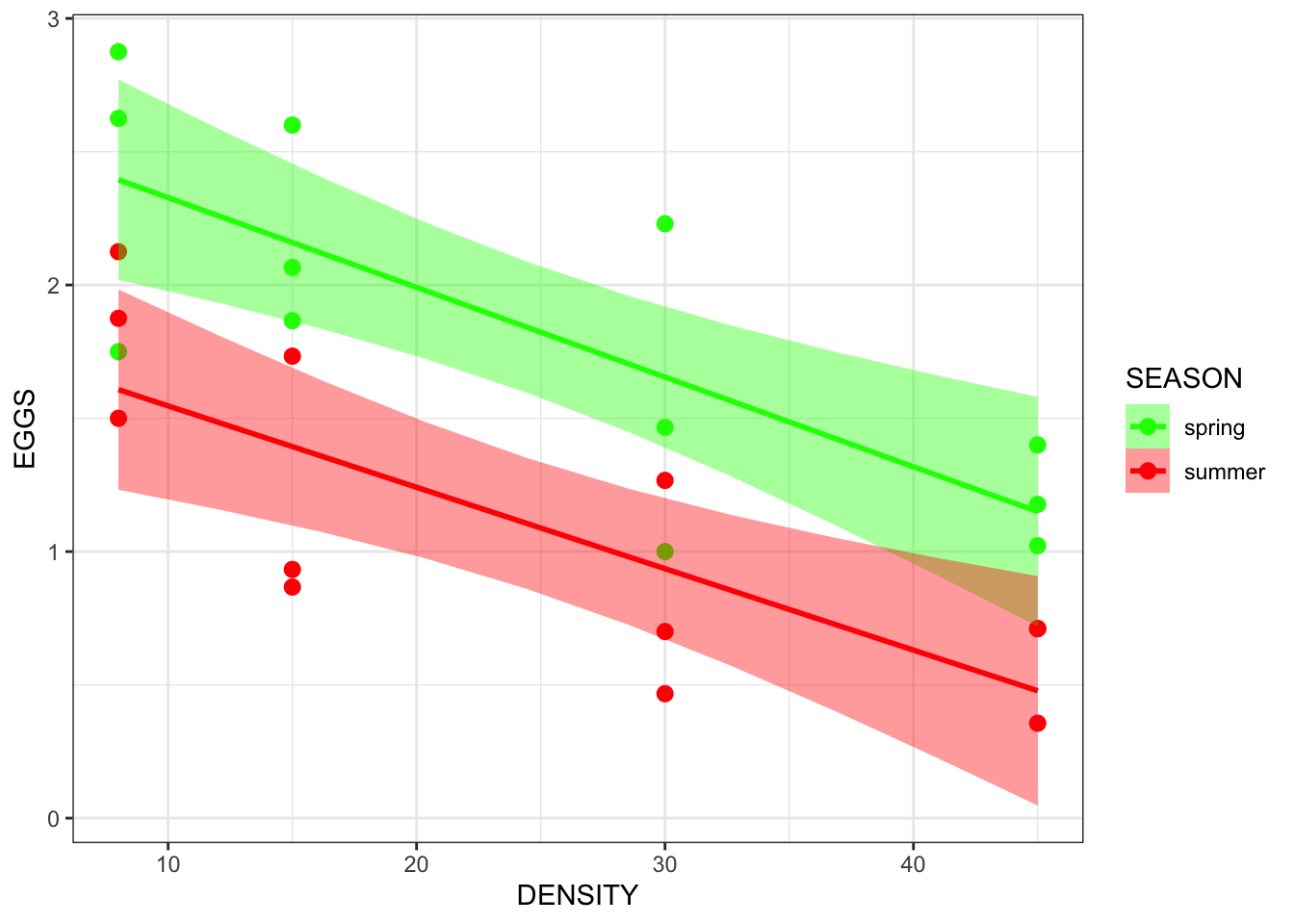
- Output observations:
- As limpet density increases, there seems to be a decrease in egg production
- There appears to be a seasonal difference in egg production in which yields are better in spring than in summer
- mathematically, the intercept (the value of egg production) at a density of 0 is higher in spring
- Thinking about this plot in terms of regression:
- y is egg production
- x is density
- b is where the line crosses the y axis (egg production when density = 0)
- m is the slope of the egg production density relationship -
- Change in egg production per unit change in density - strength of density dependence
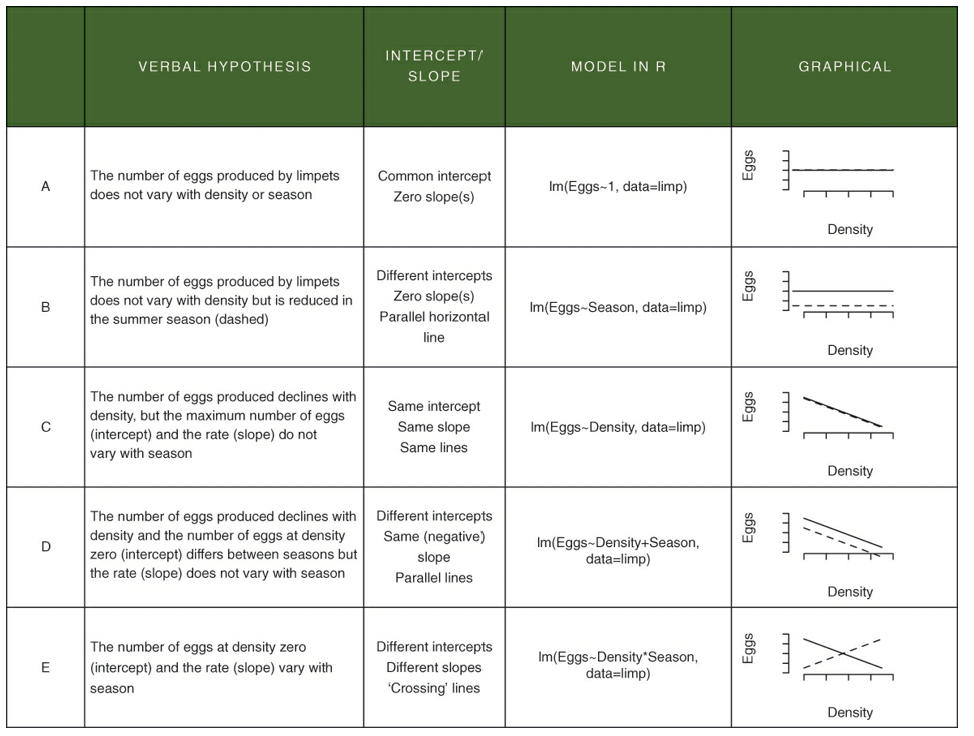
- In the above table, neither A or B reflect the data in the limpet density scatterplot
- E also does not do the data justice because the slopes are approximately parallel
- C and D are possible
- D is the best explanation of the data
- The difference between E and D is the presence (E) or absence (D) of an interaction term that specifies that the slopes are different
- An interaction would look like - “The effect on density on egg production depends on the season”
- The effect of density on egg production = slope value
- Depends on the season = values may differ depending on the season
- An interaction would look like - “The effect on density on egg production depends on the season”
6.2.1 Constructing the ANCOVA
limp.mod <- lm(EGGS ~ DENSITY * SEASON, #expression says we want model to analyze a (main) effect of DENSITY,
#a (main) effect of SEASON, and the potential for the effect of DENSITY
#to depend on SEASON (interaction )
data = limp)
limp.mod##
## Call:
## lm(formula = EGGS ~ DENSITY * SEASON, data = limp)
##
## Coefficients:
## (Intercept) DENSITY SEASONsummer
## 2.664166 -0.033650 -0.812282
## DENSITY:SEASONsummer
## 0.003114- Null hypothesis: the interaction term is not significant
- That is to say - there are no differences in the slopes for each season
- There is no extra variation explained by fitting different slopes
- That is to say - there are no differences in the slopes for each season
Fetch the coefficients (intercepts and slope estimates), the residuals, the fitted values, etc.:
names(limp.mod)## [1] "coefficients" "residuals" "effects" "rank"
## [5] "fitted.values" "assign" "qr" "df.residual"
## [9] "contrasts" "xlevels" "call" "terms"
## [13] "model"Check assumptions:
autoplot(limp.mod,smooth.colour = NA)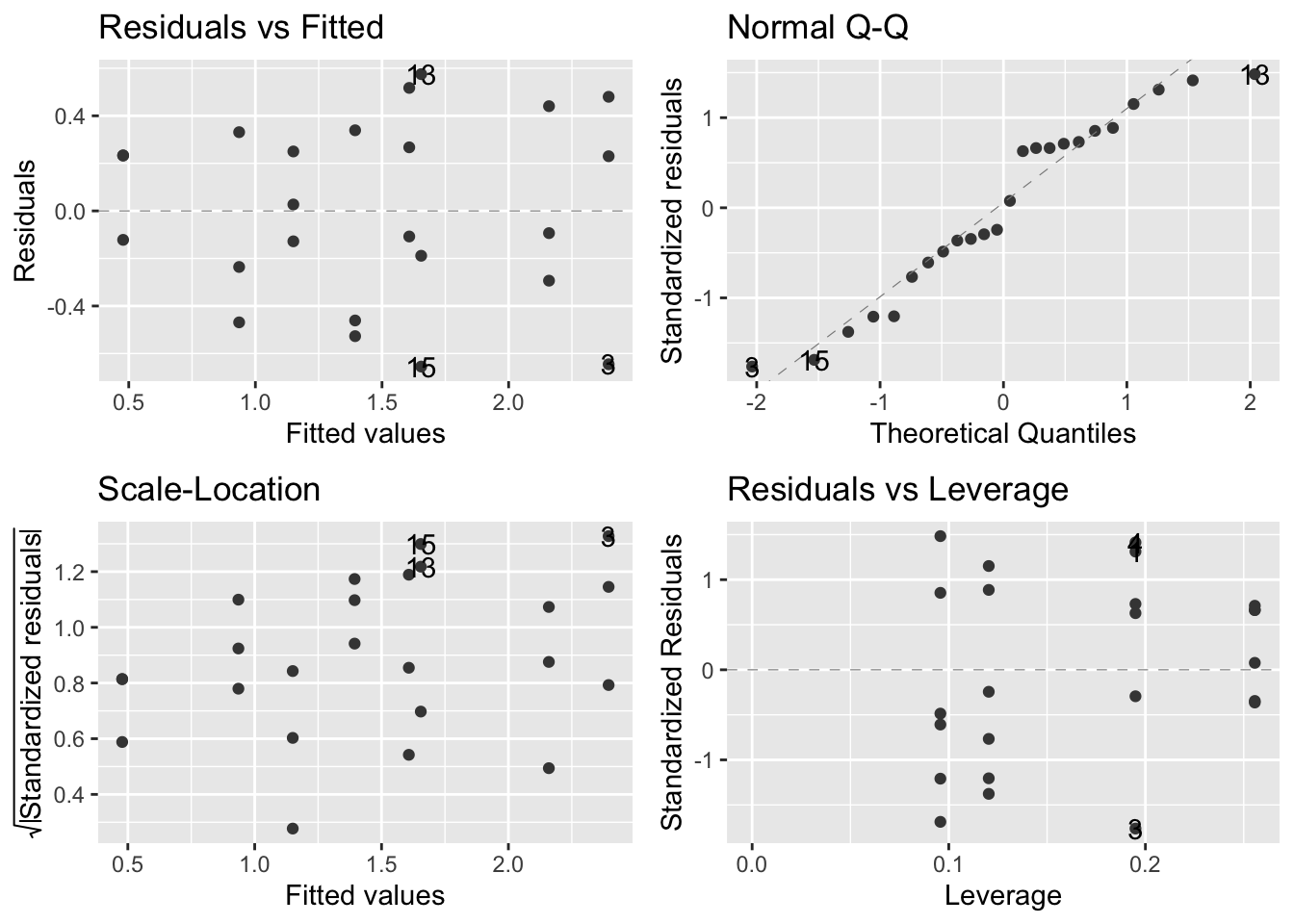
- The assumptions are met according to the above figures
Generate an anova table:
anova(limp.mod)## Analysis of Variance Table
##
## Response: EGGS
## Df Sum Sq Mean Sq F value Pr(>F)
## DENSITY 1 5.0241 5.0241 30.1971 2.226e-05 ***
## SEASON 1 3.2502 3.2502 19.5350 0.0002637 ***
## DENSITY:SEASON 1 0.0118 0.0118 0.0711 0.7925333
## Residuals 20 3.3275 0.1664
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1- output:
- big F values/small p values - DENSITY and SEASON - effects are significant/unlikely to be the result of chance
- effects of DENSITY and SEASON are additive
- small F value/big p value - DENSITY:SEASON - no interaction
- big F values/small p values - DENSITY and SEASON - effects are significant/unlikely to be the result of chance
Generate a summary table:
summary(limp.mod)##
## Call:
## lm(formula = EGGS ~ DENSITY * SEASON, data = limp)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.65468 -0.25021 -0.03318 0.28335 0.57532
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.664166 0.234118 11.380 3.45e-10 ***
## DENSITY -0.033650 0.008259 -4.074 0.000591 ***
## SEASONsummer -0.812282 0.331092 -2.453 0.023450 *
## DENSITY:SEASONsummer 0.003114 0.011680 0.267 0.792533
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.4079 on 20 degrees of freedom
## Multiple R-squared: 0.7135, Adjusted R-squared: 0.6705
## F-statistic: 16.6 on 3 and 20 DF, p-value: 1.186e-05- Upper portion of the table:
- R lists things alphanumerically (spring would be listed before summer)
- SEASONsummer is the difference between the spring and summer y intercepts
- My rough calculations estimated this to be -0.756, which is very close to their -0.81
- DENSITY:SEASONsummer is the difference between slopes for spring and summer
- In other words, it is the change in the rate of density dependence that arises from shifting from spring to summer
- In the summmer, the density dependence was only 0.003 units (egg prod/density) lower than in spring which was found not to be statistically significant
- Summer reduces egg production compared with spring, on average, by 0.812 eggs - significant
- Bottom of coefficients table:
- Adjusted R-squared (0.6705) - means that the model we have fitted explains 67% of the variation in egg production
- Low p value - the model has a signficant fit to the data p < 0.001
- Large F statistic
6.2.2 Putting the lines onto the figure
- We need to predict some y values using a sensible range of x values
- We can use the model eggs(spring) = 2.66 - 0.033 x DENSITY to accomplish this
coef(limp.mod)## (Intercept) DENSITY SEASONsummer
## 2.664166462 -0.033649651 -0.812282493
## DENSITY:SEASONsummer
## 0.003113571Build a factorial representation of variables and output a grid of numbers:
expand.grid(FIRST = c("A","B"), SECOND = c(1,2)) ## FIRST SECOND
## 1 A 1
## 2 B 1
## 3 A 2
## 4 B 2Predict y values at all provided x values:
predict(limp.mod) ## 1 2 3 4 5 6 7 8
## 2.3949692 2.3949692 2.3949692 1.6075953 1.6075953 1.6075953 2.1594217 2.1594217
## 9 10 11 12 13 14 15 16
## 2.1594217 1.3938428 1.3938428 1.3938428 1.6546769 1.6546769 1.6546769 0.9358016
## 17 18 19 20 21 22 23 24
## 0.9358016 0.9358016 1.1499321 1.1499321 1.1499321 0.4777604 0.4777604 0.4777604- 24 values returned because, 2 seasons x 4 density treatments x 3 replicates = 24
To generate a new set of x values we could use:
new.x <- expand.grid(DENSITY =
seq(from =8, to=45, #the new x values will be between 8 and 45
length.out = 10), #generates 10 new x values for each parameter
SEASON = levels(limp$SEASON)) #sets the parameter as season.
head(new.x)## DENSITY SEASON
## 1 8.00000 spring
## 2 12.11111 spring
## 3 16.22222 spring
## 4 20.33333 spring
## 5 24.44444 spring
## 6 28.55556 springWe can now embed these ‘new.x’ x values into the predict() function:
new.y <- predict(limp.mod,
newdata = new.x, #instructs R to use the new x values
interval = 'confidence') #for confidence interval around each y value (fit)
head(new.y)## fit lwr upr
## 1 2.394969 2.019285 2.770654
## 2 2.256632 1.931230 2.582034
## 3 2.118294 1.834274 2.402315
## 4 1.979957 1.724062 2.235852
## 5 1.841619 1.595998 2.087241
## 6 1.703282 1.447918 1.958646Now for some housekeeping:
addThese <- data.frame(new.x, new.y) #combines the two dfs into a single one
addThese <- rename(addThese, EGGS = fit) #changes the column name "fit" to EGGS
head(addThese)## DENSITY SEASON EGGS lwr upr
## 1 8.00000 spring 2.394969 2.019285 2.770654
## 2 12.11111 spring 2.256632 1.931230 2.582034
## 3 16.22222 spring 2.118294 1.834274 2.402315
## 4 20.33333 spring 1.979957 1.724062 2.235852
## 5 24.44444 spring 1.841619 1.595998 2.087241
## 6 28.55556 spring 1.703282 1.447918 1.958646Plot the data:
ggplot(limp, aes(x=DENSITY, y = EGGS, colour = SEASON)) +
geom_point(size = 2.5) + #specifies the size of the point
geom_smooth( #adds the regression line and the CI around the fitted line;
#assumes that x and y are the same as already specified in ggplot
data = addThese,
aes(ymin = lwr, ymax = upr, #confidence interval
fill = SEASON), #different fill depending on the SEASON variable
stat = 'identity') + #tells geom_smooth to use what is in the dataframe and not calculate anything else
scale_colour_manual(values = c(spring="green", summer = "red")) + #color for the regression line
scale_fill_manual(values = c(spring="green", summer = "red")) + #color for the confidence interval area
theme_bw()